SebastianFM
-
Postów
755 -
Dołączył
-
Ostatnia wizyta
Treść opublikowana przez SebastianFM
-
@Ryszawy, serio to pytanie do ejaja było potrzebne w tym temacie? Rzeczywiście czegoś nowego się dowiedziałeś?
-
Jak DLSS/DLAA wygładza krawędzie? W jednym i drugim przypadku każda klatka jest renderowana z różnym przesunięciem o część piksela w poziomie i w pionie. W ten sposób składając obraz z wielu klatek uzyskiwana jest wyższa rozdzielczość. NVIDIA określiła dokładnie ile powinno być użytych różnych przesunięć dla kolejnych klatek w zależności od trybu DLSS. Wzór to 8 * (współczynnik ^ 2), gdzie współczynnik to stosunek rozdzielczości wyjściowej do wejściowej. Wynika z tego, że przy DLSS Performance powinno się używać 8 * (2 ^ 2) czyli 32 różnych przesunięć a przy DLAA powinno się używać 8 * (1 ^ 2) czyli 8 różnych przesunięć. Przykładowo, nawet jeżeli zostaną użyte tylko 4 przesunięcia dla kolejnych klatek to i tak rozdzielczość obrazu po połączeniu 4 klatek zwiększa się 2 razy w poziomie i 2 razy w pionie. DLSS/DLAA łącząc wiele klatek tworzy obraz o wyższej rozdzielczości niż rozdzielczość wyjściowa, dzięki temu krawędzie są wygładzone.
-
@Dimazz, jakie dużo pracy, na co ty liczysz? Premiera za 2 miesiące to oni mogą co najwyżej poprawić jakieś większe błędy a nie grafikę.
-
@leven, przecież ja się odniosłem do tego co napisałeś, że ci się uszkodzą moduły. Sensu to nie ma ograniczanie do 6000, nikt ci nie każe puszczać tych pamięci na 7800 czy 8000, możesz spróbować 6800 lub 7200.
-
@lukadd, a ty rzeczywiście myślisz, że tym jego pamięciom zrobi różnicę w żywotności to czy będą działały na 6000 czy 6800 lub 7200? Idąc jego tokiem rozumowania to puszczone na 8000 powinny często padać a podkręcone to już 50/50. @leven, jak się tak boisz to najlepiej w ogóle nie włączaj kompa.
-
Intel Arrow Lake / Lunar Lake / Panther Lake - 15 generacja
SebastianFM odpowiedział(a) na temat w Intel
Raczej nietrafiona ta twoja ocena. Mnie tylko zastanawia czemu ktoś kupił Core Ultra 5 225.
-
@maxmaster027, do gier w które gram spokojnie wystarcza mój RTX 4070 Ti. Czekam na kolejną generację.
-
@maxmaster027, chciałem tylko doprecyzować, że automatyczne dobieranie trybu DLSS do rozdzielczości jest realizowane przez samą bibliotekę DLSS a gry, w których jest taka opcja, to po prostu korzystają z odpowiedniej funkcji z biblioteki.
-
@WJ_PR, DLSS też nie "zgaduje pikseli" tylko łączy dane z kolejnych klatek obrazu, żeby uzyskać wyższą rozdzielczość.
-
Intel Arrow Lake / Lunar Lake / Panther Lake - 15 generacja
SebastianFM odpowiedział(a) na temat w Intel
@Doamdor, a zmieniałeś może ustawienia LLC i/lub AC/DC Loadline? Niedostosowana wartość DC Loadline do LLC właśnie powoduje nieprawidłowe raportowanie poboru mocy. -
Skoro dobrą mapę zrobili dopiero po krytyce graczy to na co poszedł ten cały rekordowy budżet gry (400 mln $). Nie było jakiejś kontroli jakości? A kto robił mapy, praktykanci czy może AI?
-
AMD ZEN 5 (SERIA RYZEN 9xxx / SOCKET AM5) - wątek zbiorczy
SebastianFM odpowiedział(a) na Ogider temat w AMD
@sideband, to już jest frajerstwo, że kolejny raz wymyślasz o mnie bzdury i kłamiesz na mój temat. -
AMD ZEN 5 (SERIA RYZEN 9xxx / SOCKET AM5) - wątek zbiorczy
SebastianFM odpowiedział(a) na Ogider temat w AMD
@ju-rek, poszukasz? Czyli to znaczy, że na jednym i drugim systemie mogłeś mieć zupełnie inne ustawienia procesora i pamięci. Jaką wartość ma takie porównanie? -
Podkręcanie pamięci DDR5 (Wszystkie platformy)
SebastianFM odpowiedział(a) na KamileN temat w Pamięci RAM
@Pentium D, opóźnienie nadal tragiczne. 😁 -
AMD ZEN 5 (SERIA RYZEN 9xxx / SOCKET AM5) - wątek zbiorczy
SebastianFM odpowiedział(a) na Ogider temat w AMD
@sideband, wiem, że nie ma, to tylko pomyłka przy pisaniu. Nie masz racji z tą wydajnością, na żadnej wersji Windows 11 nie uzyskasz takiej wydajności jak na Windows 10. Sprawdzałem co najmniej 5 różnych wersji Windows 11 21H2, włącznie z pierwszą. Na każdej wersji w takich powtarzalnych testach jak np. wbudowany benchmark SotTR czy Cyberpunk 2077 jest zawsze niższy wynik niż w Windows 10 22H2. O jakim syfie ty piszesz? To nie ma nic do rzeczy. Ja zawsze wyłączam wszystko co mogłoby mieć negatywny wpływ na wydajność. -
AMD ZEN 5 (SERIA RYZEN 9xxx / SOCKET AM5) - wątek zbiorczy
SebastianFM odpowiedział(a) na Ogider temat w AMD
@Zachy, ja bym na to nie liczył. Od kiedy wprowadzili tą zmianę to żadna nowsza wersja Windows nie ma takiej wydajności jak Windows 10 22H2, nawet ten pierwszy Windows 11 21H1 ma niższą. Sprawdzałem ostatnio 26H1 i nic się nie poprawiło. Ja robiłem testy napisanym przeze mnie prostym programem i wiem co dokładnie powoduje niższą wydajność. Według mnie ma to związek z energooszczędnością. -
Odkryłeś Amerykę. 🙂
-
Intel Nova Lake, Razer Lake, Hammer Lake - LGA-1954
SebastianFM odpowiedział(a) na Kartofel temat w Intel
@leven, ten problem to jest tylko w twojej głowie. Znowu to narzekanie. Jak ci tak bardzo nie pasują rdzenie E to możesz je wyłączyć. Poza tym czemu w takim razie nie wziąłeś AMD? -
AMD ZEN 5 (SERIA RYZEN 9xxx / SOCKET AM5) - wątek zbiorczy
SebastianFM odpowiedział(a) na Ogider temat w AMD
To ty przeczytaj te komentarze a nie opowiadasz bajki. W ostatnim czasie potrafili ludziom anulować normalne zamówienia bez powodu, poza tym sprzedają towar, którego nie mają na stanie. Mogę się założyć, że ci anulują. -
AMD ZEN 5 (SERIA RYZEN 9xxx / SOCKET AM5) - wątek zbiorczy
SebastianFM odpowiedział(a) na Ogider temat w AMD
@Pitt_34, wystarczy przeczytać komentarze o sprzedającym, żeby wiedzieć, że nie wyślą. -
Intel Nova Lake, Razer Lake, Hammer Lake - LGA-1954
SebastianFM odpowiedział(a) na Kartofel temat w Intel
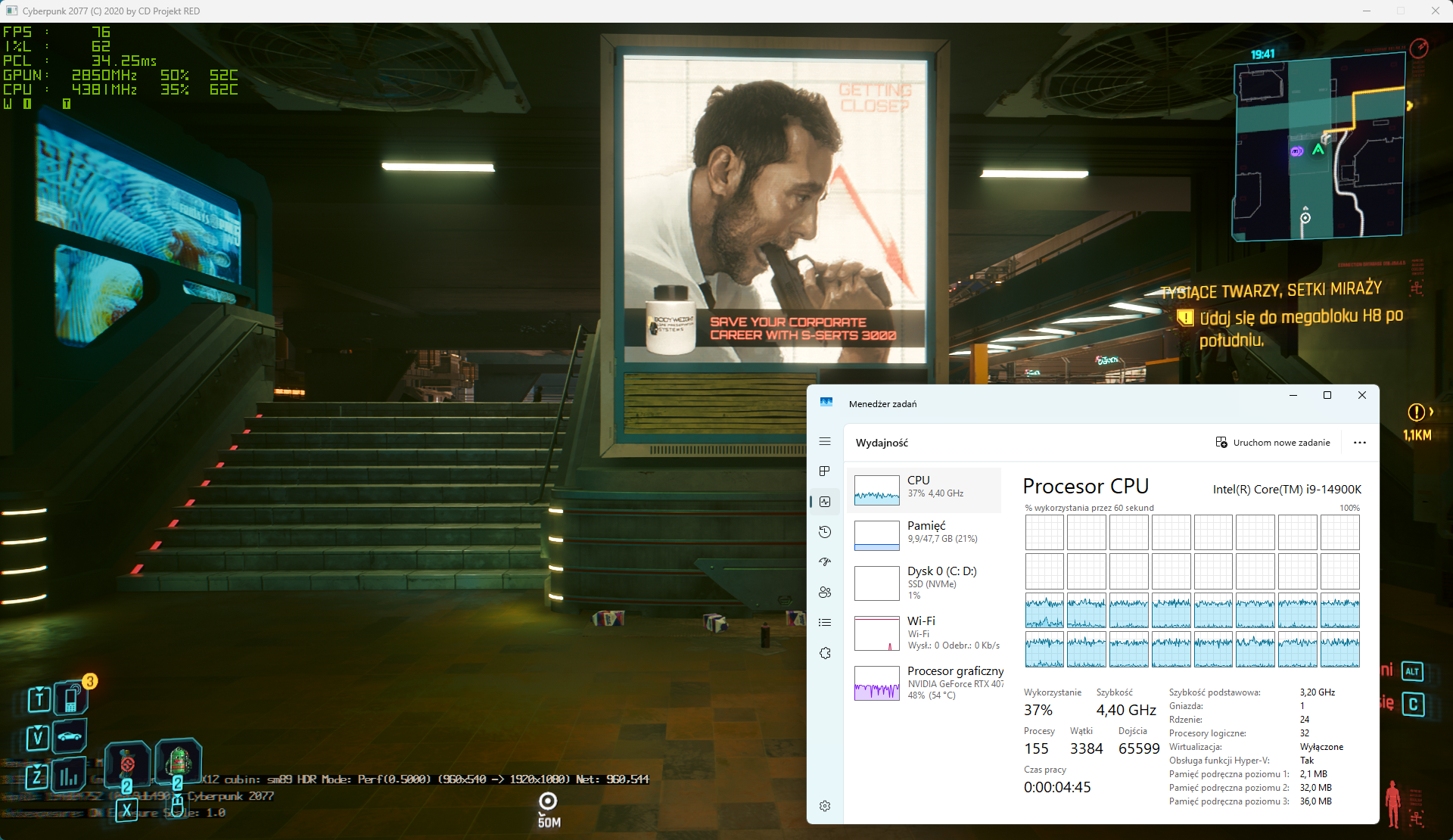
@sideband, programy i niektóre gry można uruchomić na rdzeniach E tak żeby działały dokładnie tak jakby rdzenie P były wyłączone. 1. Powinno się ograniczyć liczbę równoległych wątków uruchamianych przez grę. Jeżeli gra jest uruchamiana na rdzeniach E to powinna korzystać z 16 zamiast 32 równoległych wątków. Np. w Battlefield 6 można ustawić liczbę wątków za pomocą user.cfg, w Cyberpunk 2077 uruchamiając grę z odpowiednim argumentem wiersza poleceń. Ja napisałem mały program na własny użytek, który podczas uruchamiania gry podmienia funkcję używaną przez grę do sprawdzania liczby rdzeni procesora. Oszukuje on w ten sposób grę, że procesor ma tylko 16 rdzeni E przez co gra nie tworzy i nie uruchamia więcej niż 16 równoległych wątków. 2. Ustawienie koligacji na rdzenie E. 3. Dodatkowo można wpisem w rejestrze zarezerwować rdzenie P tak, żeby nawet system na nich nic nie uruchamiał. Nie trzeba wtedy nawet korzystać z koligacji. Cyberpunk 2077, ustawienia Ray Tracing: Ultra, miejsce testowe @tomcug'a, uruchomiony w 16 wątkach na rdzeniach E.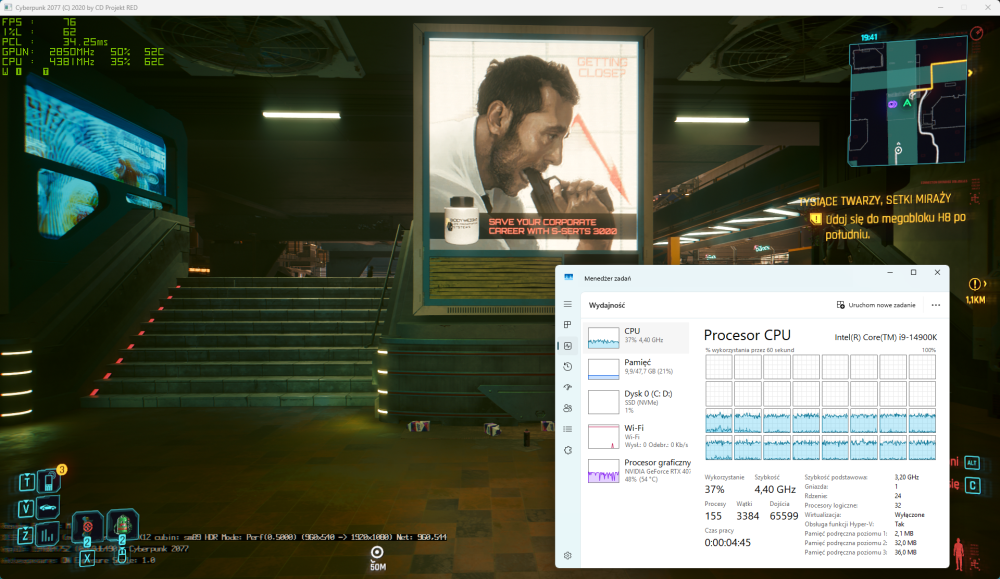
-
AMD ZEN 5 (SERIA RYZEN 9xxx / SOCKET AM5) - wątek zbiorczy
SebastianFM odpowiedział(a) na Ogider temat w AMD
Tylko, że to jest mniej niż 5% różnicy. -
AMD ZEN 5 (SERIA RYZEN 9xxx / SOCKET AM5) - wątek zbiorczy
SebastianFM odpowiedział(a) na Ogider temat w AMD
@Kadajo, na tej samej zasadzie mógłbyś jechać po 9950X3D a jednak tego nie robisz. Procesor ma dużo rdzeni, gra wykorzystuje wszystkie dostępne więc pobór mocy jest wyższy. To nie jest wina Intel'a chociaż mogli pomyśleć i zrobić procesor typowo dla graczy, np. tylko 8 rdzeni P z HT albo 8 rdzeni P bez HT i 8 rdzeni E. Swoją drogą jak każda trochę ogarnięta osoba da radę ustawić ten procesor typowo pod gry, ograniczając znacznie pobór mocy i nie tracąc wydajności. Co ma na celu twoje narzekanie? -
AMD ZEN 5 (SERIA RYZEN 9xxx / SOCKET AM5) - wątek zbiorczy
SebastianFM odpowiedział(a) na Ogider temat w AMD
130 W różnicy czyli to znaczy, że porównujesz i7-14700K na domyślnych, bardzo nieoptymalnych ustawieniach z 9800X3D po UV inaczej nie ma szans, żeby było aż tyle. W ogóle to bez sensu porównywać 8 rdzeniowy procesor z 20 rdzeniowym procesorem skoro wiadomo, że dodatkowe rdzenie nie zwiększą wydajności w grach a tylko zwiększają pobór mocy. Poza tym @Kadajo bardzo przesadza z tym, że tego procesora nie da się schłodzić. Nawet na domyślnych ustawieniach pobór mocy podczas gry nie jest taki, żeby zwykłe chłodzenie powietrzne sobie nie poradziło.