AMDK11
-
Postów
115 -
Dołączył
-
Ostatnia wizyta
Treść opublikowana przez AMDK11
-
Myślę, że duże zyski są możliwe, ale to zależy od priorytetów. Priorytetem AMD w tej chwili jest więcej rdzeni. Z tego, co wiem, nic nie stoi na przeszkodzie, aby x86 osiągnęło znacznie wyższy IPC niż obecnie. Chociaż x86 komplikuje projekt, osiągnięcie IPC obecnego i przyszłego rdzenia ARM jest dla x86 całkowicie możliwe. Apple może teraz mieć znacznie wyższy IPC, ale projekt i techniki zastosowane w jego mikroarchitekturze nie są tak zaawansowane, jak na przykład Zen5(m.in predyktor(BPU)). Ściśle kontrolując proces pisania kodu oprogramowania, Apple upraszcza mikroarchitekturę rdzenia, co przenosi większy narzut na wysiłek pisania softu. W przypadku x86 projektanci rdzeni muszą jednak wykazać się umiejętnościami i pomysłowością a nawet geniuszem, aby poradzić sobie z uniwersalnością, zmienną długością i chaotyczną naturą instrukcji w każdym strumieniu oprogramowania. Z drugiej strony, x86 jest znacznie bardziej wszechstronny i nawet dodając nowe instrukcje nie trzeba się martwić, że nowy rdzeń x86 z nowymi instrukcjami nie będzie już kompatybilny z poprzednim oprogramowaniem. Moim zdaniem ciągłe spory i kłótnie o to, który x86 czy ARM jest lepszy, są bezcelowe. Apple Mx to inny cel i bardzo wąska grupa użytkowników. 99% z nich nie ma pojęcia, jaki procesor jest w nim zainstalowany ani jaką ma mikroarchitekturę. Nikogo nie obchodzi, czy osiągnął daną wydajność przy taktowaniu 2 GHz czy 10 GHz, czy ma cztery, czy dziesięć potoków dekodujących na rdzeń itd. Priorytety rynku x86 są zupełnie inne, ponieważ ARM nie stanowi znaczącej konkurencji. Dla AMD i Intela priorytetem są procesory Epyc/Xeon i urządzenia mobilne. AMD projektuje x86 Zen z silnym naciskiem na Epyc, o czym świadczy Zen5, który także musi działać dobrze w mobile. Oczekuje się, że Zen6 przyniesie mniejsze ulepszenia, ale między innymi o 50% więcej rdzeni i pamięci podręcznej. Prawdopodobnie trochę zwiększy taktowanie. Dodając więcej rdzeni i pamięci podręcznej, AMD musi zrównoważyć złożoność samych rdzeni. Apple ma tylko kilka dużych rdzeni na chip, co zapewnia większą swobodę rozbudowy mikroarchitektury. Co więcej, Apple spowolniło teraz rozbudowę rdzenia i zwiększa taktowanie. AMD i Intel walczą ze sobą o osiągnięcie jak największej ilości rdzeni na gniazdo, co zostawia małe pole do rozbudowy. Intel już zaprojektował potężny rdzeń, 3-4 razy bardziej złożony niż GoldenCove i prawdopodobnie bardziej rozbudowany i szerszy niż jakikolwiek ARM, ale porzucił projekt, ponieważ nie chciał marnować krzemu wyłącznie na procesory do komputerów stacjonarnych lub urządzeń mobilnych, gdzie można było wykorzystać prostsze rdzenie i osiągnąć „stały” wzrost generacyjny. AMD i Intel to korporacje, a akcjonariusze chcą widzieć stały, niezawodny i stabilny wzrost. Bardzo duży wzrost złożoności rdzeni w ciągu jednej generacji oznacza dłuższy czas projektowania i walidacji oraz większe ryzyko błędów. AMD i Intel mają własną ścieżkę rozwoju dla x86. Siła x86 tkwi we wstecznej kompatybilności, uniwersalności i miliardowych ilości softu(w tym otwartych i darmowych) działających natywnie na x86.
-
To jest TigerLake, czyli rdzenie WillowCove(x86 SunnyCove z przeprojektowanym podsystemem cache L2), ale z 1,25 MB pamięci podręcznej L2 (non-Inclusive) zamiast 512 KB (0,5 MB) (Inclusive). CometLake(rdzenie x86 Skylake) ma tak jak poprzednie generacje L2 typu Inclusive. Pamięć non-Inclusive to ten sam typ pamięci, który zastosowano w Skylake-X, który w części aplikacjach odnotował regresję w porównaniu z oryginalnym Skylake-S. Średni IPC WillowCove z pamięcią podręczną L2 non-Inclusive jest o około 5% niższy niż SunnyCove z pamięcią podręczną L2 Inclusive, ale TigerLake ma znacznie wyższe taktowanie. Podejrzewam, że Intela proces litograficzny 10nm charakteryzował się raczej niskim uzyskiem i słabymi parametrami, aby nadawał się do procesorów stacjonarnych. Woleli skupić produkcję 10nm dla mobilnych układach IceLake(SunnyCove), TigerLake(WillowCove) i serwerowych Xeon. IceLake jak i TigerLake jest niestety tylko na BGA. Prawdopodobnie RicketLake ma IMC(Kontroler RAM) żywcem przeniesiony z mobilnego IceLake. Kontroler RAM i Ring-Bus są słabym ogniwem RocketLake w skalowaniu dla 8 rdzeni. Ale pojedynczy wątek osiąga konkretny wzrost IPC(Średni IPC INT ~16% i FP ~24%), jakiego można spodziewać się po nowej generacji.
-
A ja głupi myślałem że będzie owalny lub w krztałcie przekroju jajka
-
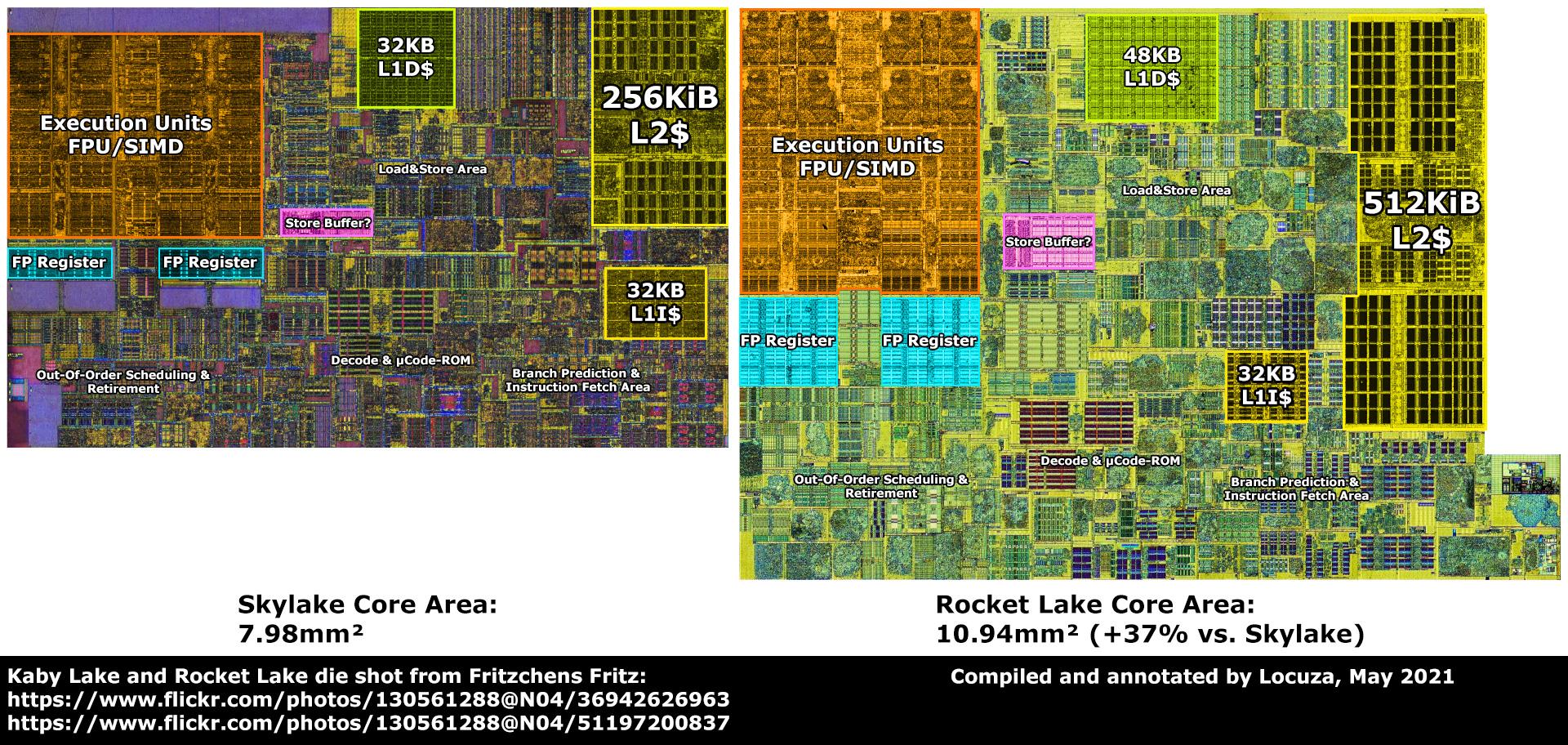
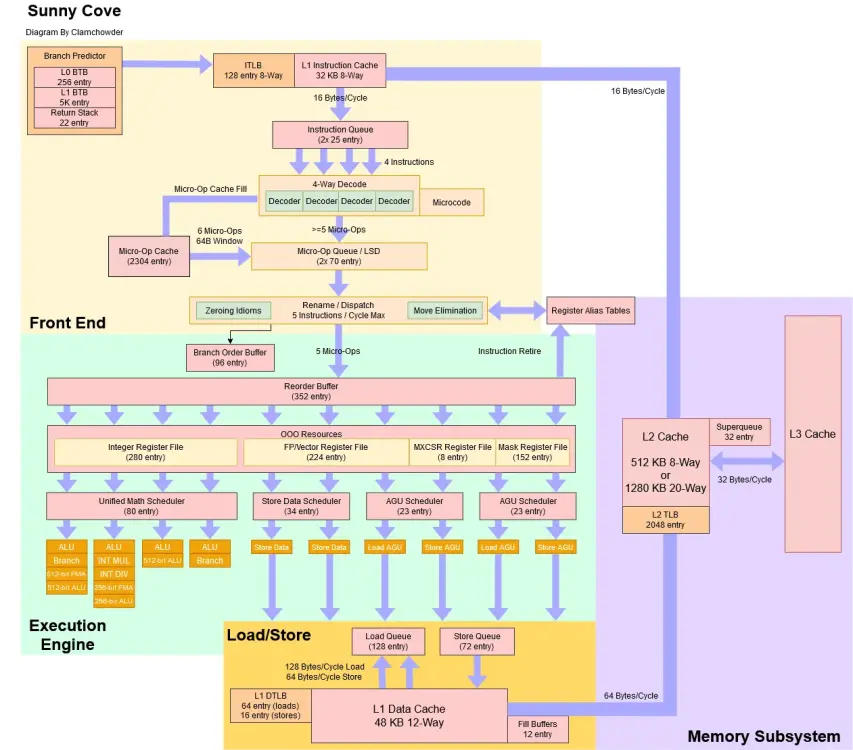
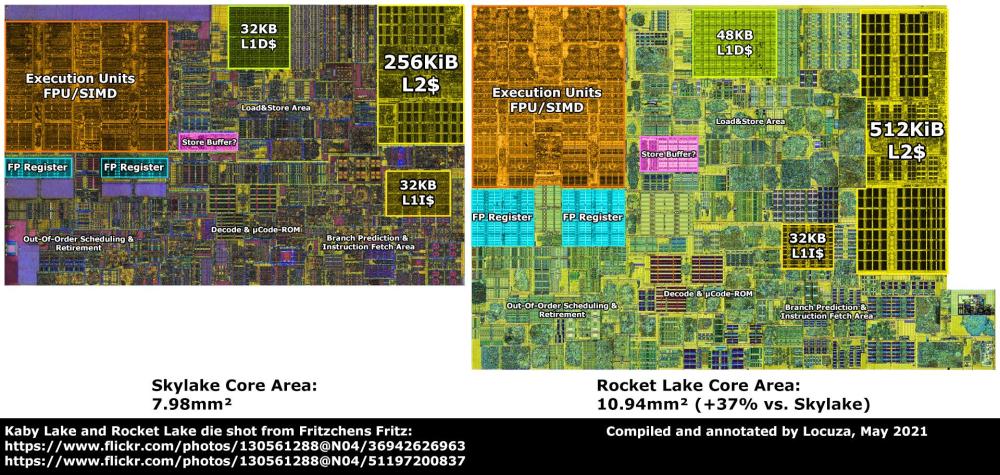
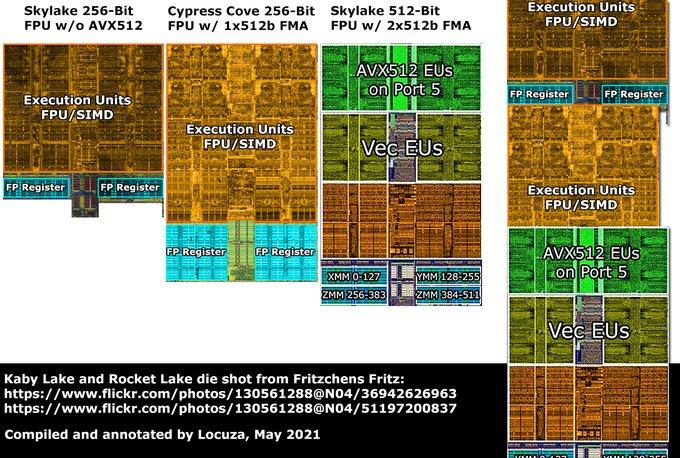
RocketLake bazuje na rdzeniach SunnyCove x86 przeniesionych(1:1) z 10 nm do 14 nm pod nazwą kodową CypressCove. Rdzeń SkyLake składa się z 217 milionów tranzystorów. Rdzeń CypressCove składa się z ~300 milionów tranzystorów, co oznacza, że jest bardziej złożony od Skylake o 38%. Rdzeń CypressCove x86 (SunnyCove) to kolejny duży skok generacyjny po SkyLake. CypressCove ma średni wzrost IPC dla pojedynczego wątku (ST) Integer (ALU) o 15-16%, a wzrost FP wynosi ~24%! Na dodatek ma implementację AVX512!(podobną do tej z Zen4 czyli 2x256bit) Ale CometLake, pomimo przestarzałych rdzeni, ma ich o 25% więcej, co przeważa nad zyskami IPC i słabym skalowaniem (szczególnie INT) CypressCove. Problemem w RocketLake jest skalowanie Integer dla wszystkich 8 rdzeni, co daje ~5% zysku w porównaniu do 8 rdzeni Skylake. Jeśli chodzi o FPU, skalowanie jest znacznie lepsze, ponieważ osiąga wzrost o 16-18%. Problemem jest prawdopodobnie m.in niższa prędkość zegara Ring-Bus. Mikroarchitektura SkyLake pojawiła się w 2015 roku, a prace nad SunnyCove startowały w 2016 roku i trwały do około 2018 roku. Rdzeń Cypress/SunnyCove jest bardziej zaawansowanym rdzeniem x86 niż SkyLake. Przegrywa, ponieważ RocketLake maksymalnie ma do 8 rdzeni względem 10-rdzeniowego Skylake w CometLake. Czemu tak jest? Odpowiedź na to jest bardzo prosta. 8 rdzeni CypressCove w 14 nm, zajmuje powierzchnię taką jak hipotetyczny 11-rdzeniowy Skylake!!! Gdyby RocketLake miał 10 rdzeni zajmowałby powierzchnię porównywalną z 14 rdzeniami Skylake!!! Praktycznie zawsze, przy dużej rozbudowie rdzenia, przechodzisz na niższy proces litograficzny, który kompensuje większą złożoność projektu (tj. więcej bramek logicznych (tranzystorów)). W przypadku RocketLake proces litograficzny pozostał taki sam jak w CometLake, a to zawsze skutkuje drastycznymi kompromisami, których końcowy efekt wygląda tak jak wygląda. Jeśli chodzi o mnie, gdybym miał wybierać, wziąłbym RocketLake, którym fajnie byłoby się pobawić, bo jestem entuzjastą. CypressCove to zdecydowanie bardziej zaawansowany rdzeń x86, w porównaniu do już wyeksploatowanej i serwowanej do znudzenia przez Intel mikroarchitektury SkyLake. Ale to zależy od tego, czego oczekujesz i czy te dane mają dla Ciebie znaczenie. RocketLake-S 8 Rdzeni: Porównanie układu krzemowego CometLake-S 10 rdzeni do RocketLake-S 8 rdzeni: W Cinebench 2024: ST 1 rdzeń Skylake 78p MT 10 rdzeni Skylake 792p(+1.8%) ST 1 rdzeń CypressCove 100p(+28%!!!) MT 8 rdzeni CypressCove 778p EDIT: Intel Microarchitecture Cache Comparison Component Haswell Skylake Sunny Cove L1D Cache 32KiB 32KiB 48KiB L2 Cache 256KiB 256KiB 512 KiB L2 TLB 1024 1536 16 (1G)2048 (4K) 1024 (2M/4M) 1024 (1G) µOP Cache 1.5KµOPs 1.5KµOPs 2.25KµOPs Intel Microarchitecture Cache Comparison Component Haswell Skylake Sunny Cove ROB 182 224 352 In-flight loads 72 72 128 In-flight stores. 42 56 72 Porównanie powierzchni tej samej mikroarchitektury tylko w różnych procesach litograficznych SunnyCove(10nm) i CypressCove(14nm):



-
DiamondRapids 192 rdzenie P:

-
NovaLake?

-
Nie mam problemu, bo mam platformę AM5 i Ryzen 5 9600X. Czekam ze stoickim spokojem, jak rozwinie się sytuacja między Zen6 i NovaLake
-
Zen6
-
ArrowLake(LionCove) ma problem z LLC(L3). Jak wspomniałem wcześniej: Rdzeń LionCove L3 36MB (U9 285K) 84 cykle 1T - 57 GB/s nT - ~1 TB/s Rdzeń Zen5 L3 32MB x2 (9900X 2x6 rdzeni) 48 cykli 1T - 173 GB/s nT - 1,6 TB/s Ogólnie rzecz biorąc, uważam, że mikroarchitektura Zen5 jest bardziej zaawansowana pod względem m.in. ogromnego i skutecznego predyktora, skupiając się na bardzo niskich opóźnieniach i inteligentniejszym wykorzystaniu dostępnych(mniejszych m.in buforów względem LionCove) zasobów itd. Jestem pewien, że Zen6 będzie kolejnym dobrym skokiem od nowej bazy jaką jest Zen5 dla przyszłych generacji. Nie wiem, czy NovaLake wykorzysta nowe rdzenie, czy raczej dokona niewielkiej ewolucji w porównaniu do LionCove. Jedno jest pewne: jeśli nie ulepszą komunikacji L3 i Ring-Bus lub nie przejdą na typ Mash, to nie sądzę, żeby 1T przyniósł duże korzyści, co jest bardzo ważne w synchronizacji danych i komunikacji między rdzeniami. Dwa razy więcej rdzeni i tak przyniesie duże korzyści, ale niekoniecznie takie, jakich byśmy chcieli. Edit: Intel, wraz z prezentacją LionCove (również nowej bazy dla przyszłych generacji), pokazał animację możliwości skalowania podzielonych potoków harmonogramu do co najmniej 10ALU i 8FP, które Intel najprawdopodobniej rozłoży na dwie duże generacje. GoldenCove (i pochodne) dekoder x86 6-Wide, 3ALU-FP + 2ALU (który działa jak 5ALU lub 3FP + 2ALU ), 5AGU(3Load + 2Store), 2StoreData LionCove(nowa baza) dekoder x86 8-Wide, 6ALU, 4FP, 6AGU(3Load + 3Store), 2StoreData Zen4 dekoder 4-Wide, 4ALU(w tym 1ALU/Branch)+1Branch, 4FP+2FStore/F2I, 3AGU Zen5 (nowa baza) dekoder x86 2x4-Wide, 6ALU, 4FP + 2StD/IntD, 4AGU(pomimo mniejszej ilości AGU, Zen5 osiąga wyższą przepustowość). NextCove dekoder x86 10-Wide/2x5-Wide(?), 8ALU, 6FP(To jest maksimum, jakie Intel osiągnie w swojej kolejnej dużej generacji rdzeni P, a dane te są raczej prawdopodobne i nie są przesadzone) Żeby nie było to tylko uproszczone i ogólnikowe dane, bo gdybym miał wymienić wszystkie różnice i aspekty złożoności rdzeni obliczeniowych x86, strona by nie wystarczyła i wiele osób by się zanudziło. Możliwe jest również, że NovaLake nie otrzyma jeszcze tak rozbudowanego rdzenia i skalowanie to może być rozłożone na więcej niż 2 generacje. Tak czy inaczej spodziewam się niższego opóźnienia L3 i znacznie wyższej przepustowości niż ArrowLake, w przeciwnym razie nie będzie to zbyt interesujące(Bardzo wysokie IPC LionCove zostało zachamowane kiepskim L3). Chyba że dodadzą dodatkowy L3 w stylu 3D V-Cache AMD. EDIT2: Zen5 ma gigantyczny i bardzo zaawansowany predyktor(BPU) nowej generacji: 2-taken, 2-ahead, TAGE. Oznacza to, że jest w stanie niezależnie przewidzieć dwa kolejne skoki (2-ahead) i je pobrać (2-taken). Zen5 widzi znacznie dłuższe, bardzo złożone wzorce rozgałęzień i to jednocześnie dla 2 kolejnych skoków w kodzie przez co może mieć otwarte 3 okna rozgałęzień. L1 BTB 16K wpisów!!!(10.6x więcej niż Zen4!!!) L2 BTB 8K wpisów Return Address Stack 2x52 wpisy (104 dla SMT) Dla porównania, Zen4 analizuje tylko jeden skok i może pobrać tylko jeden (1-taken) ze znacznie krutszymi i prostszymi wzorcami. L1 BTB 1.5K wpisów L2 BTB 7K wpisów Return Address Stack 32 wpisy LionCove może przewidzieć dwie gałęzie, ale musi odrzucić jedną jako nieprawidłową i pobrać tylko jedną, a także widzi znacznie krutsze i mniej złożone wzorce. Zaletą jest niskie opóźnienie, szybkie wykonywanie prostszych mniej złożonych rozgałęzień w kodzie. L0 BTB 256 wpisów L1 BTB 6K wpisów L2 BTB 12K Return Address Stack 24 wpisy GoldenCove L0 BTB 128 wpisów L1 BTB 5K wpisów L2 BTB 12K wpisów Return Address Stack ~2 wpisy
-
@sniper76 Było już pewne wsparcie, ale od tego czasu wydano kilka poprawek, więc pierwszym krokiem powinno być zainstalowanie najnowszej wersji BIOS-u. Edit: F1 już wspierał Ryzen 9000, ponieważ X870B został wydany z myślą o Zen5, ale F3i nie ma już w bazie danych BIOS-u tej płyty głównej. Są za to F3a, F3h i F3. Może F3i był biosem z poważnymi błędami i go wycofano(tylko spekuluje).
-
@sniper76 dobrze napisał. Bios i sterowniki to podstawa. Z tego co widzę ma F3i, a najnowsze to F6 i F7b. Po drodze był jeszcze F4. [F4] 10.17 MB 2025-05-05 mb_bios_x870e-aorus-elite-wifi7_8arpl323_f4.zip Checksum : AFAB Update AMD AGESA 1.2.0.3a PatchA. Please also update AMD Chipset Driver to 7.01.08.129 or later version to improve gaming performance for 2CCD Ryzen 7000 & 9000 CPUs Optimized memory compatibility Enhanced PCIe compatibility Fix AMD CPU microcode signature verification vulnerability (CVE-2024-36347) for Ryzen 8000, 7000 series CPU [F6] 10.17 MB 2025-06-08 mb_bios_x870e-aorus-elite-wifi7_8arpl323_f6.zip Checksum : C9D1 Update AMD AGESA 1.2.0.3b PatchC Enhance memory compatibility [F7b] 10.22 MB 2025-06-22 mb_bios_x870e-a-elite-wifi7_8arpl323_f7b.zip Checksum : ED7B Update AMD AGESA 1.2.0.3e PatchA for new Ryzen 9000 series CPU support Fix TPM2.0’s out-of-bounds read vulnerability (CVE-2025-2884) Fix AMD CPU microcode signature verification vulnerability (CVE-2024-36347), add Ryzen 9000 series CPU support Enhance memory compatibility Stąd można bobrać BIOS: https://www.gigabyte.pl/products/page/mb/X870E-AORUS-ELITE-WIFI7/support#support-dl Nie wiem czemu nie zrobił tego zaraz po wymianie procesora, ale zaczął od ustawień UEFI. Ja bym jeszcze postawił czystą instalkę systemu + instalacja najnowszych sterowników (dla świętego spokoju) Ostatnio złożyłem jednostkę centralną na AM5, ale z Ryzen 5 9600X na płycie głównej ASUS. Pierwszą rzeczą jaką zrobiłem było wgranie najnowszego BIOS-u z Pendrive'a USB ponieważ płyta bazuje na B650-E. Też jestem na etapie poznawania platformy z tym że chcę zostawić na ustawieniach fabrycznych bez OC. No może RAM na 6000 zamiast 5600. Ostatnim moim stacjonarnym PC był Core i7 5820K na LGA2011-v3. Zen5, wbrew pozorom, jest zupełnie nową mikroarchitekturą w porównaniu do Zen4, więc do prawidłowego działania wymaga najnowszego BIOS-u i sterowników systemowych z najnowszymi poprawkami(m.in mokrokod) + lepszego wsparcia dla pamięci RAM.
-
Zdziwiłbyś się, ile problemów może sprawić zasilacz z mocą na styk dopasowaną do poboru komponentów. Zwłaszcza, że pracuje w takich warunkach latami. O zasilacz zapytałem profilaktycznie. Jeśli jeszcze nie odpowiedział, to znaczy, że być może już rozwiązał problem lub inne rzeczy są ważniejsze.
-
Mógłby podać markę i model zasilacza na wszelki wypadek. Wbrew pozorom zasilacz często może być problemem, a nowy nie zawsze oznacza automatycznie w 100% sprawny. Zwłaszcza jeśli ma stary/używany i tani model(zużycie komponentów elektrycznych/elrktronicznych m.in kondensatorów). Są zasilacze z czarnej listy i nie każdy musi być tego świadomy. Podobnie jak w pewnym (internetowym) owocowym sklepie (nie wiem, jak to teraz wygląda) polecano do gotowców wątpliwej jakości zasilacz za 250 zł(słabej jakości komponenty) do jednostki centralnej (za 9 tys. zł+) z kartą graficzną z wysokiej półki wydajnościowej, co jest proszeniem się o problemy w bliżej nieokreślonym czasie. Zwłaszcza jeśli taki zasilacz pracuje na granicy mocy 80-100%. W najtańszych konstrukcjach nawet aktywacja zabezpieczeń może być loterią. Raz zadziała, a innym razem zabierze ze sobą resztę podzespołów. Zasilacze to obszerny temat a ja poruszyłem tylko niektóre aspekty. To tyle w kwestii oszczędności na zasilaniu, które przecież jest podstawą i kluczowym elementem jednostki centralnej. Zasilacz najrzadziej się wymienia i często służy wiele lat. Warto więc poszukać takiego dobrej marki(korzystającej z dobrej jakości platformy OEM) i dopłacić te 200-300+ zł. Edit: Z drugiej strony, bez zobaczenia, jak ktoś składa komputer, znalezienie przyczyny często przypomina błądzenie po omacku. Kiedy składam sam, wiem od A do Z, co było podłączone i jak. Czasami wystarczy źle podpiąć m.in RAM, wtyczkę zasilania lub nie podpiąć np dodatkowe zasilanie CPU i jest problem. Pozornie są to rzeczy głupie i proste, ale mogą się zdarzyć. To już tak na marginesie.
-
Jaki masz zasilacz?
-
Platforma AM5 jest bardziej kusząca niż kiedykolwiek, nawet jeśli tymczasowo zainstalujesz na niej Zen4!
-
Zdjęcie struktury ArrowLake lepszej jakości: https://pbs.twimg.com/media/GqL1cYNXEAErJxN?format=jpg&name=large Wkońcu można zobaczyć szczegóły logiki rdzeni LionCove i Skymont. https://www.pcgameshardware.de/Core-Ultra-7-265K-CPU-280895/Specials/Test-Gaming-Benchmark-vs-9800X3D-1471332/
-
-
Już dawno pojawiały się opinie, że w Intelu jest zbyt wiele niepotrzebnych stanowisk, chaos i problem z kordynacją zespołów projektowych. Mam nadzieję, że Lip-Bu Tan oczyści Intela i przywróci do "normalności" jak Lisa Su AMD.
-
"Stawanie się firmą skoncentrowaną na inżynierii Musimy wrócić do korzeni i dać naszym inżynierom większe uprawnienia. Dlatego podniosłem nasze podstawowe funkcje inżynierskie do ET. A wiele zmian, które będziemy wprowadzać, ma na celu zwiększenie produktywności inżynierów poprzez usunięcie uciążliwych przepływów pracy i procesów, które spowalniają tempo innowacji. Aby dokonać niezbędnych inwestycji w nasze talenty inżynierskie i plany technologiczne, musimy znaleźć nowe sposoby na obniżenie naszych kosztów. Chociaż w zeszłym roku podjęliśmy znaczące działania, nasza obecna struktura kosztów nadal znacznie przewyższa konkurencyjne standardy. Mając to na uwadze, obniżyliśmy nasze cele dotyczące wydatków operacyjnych i nakładów kapitałowych na przyszłość, o czym opowiem podczas dzisiejszej popołudniowej rozmowy z inwestorami. Spłaszczanie organizacji Skupiając się na inżynierii, usuniemy również złożoność organizacyjną. Wiele zespołów ma osiem lub więcej warstw głębokości, co tworzy niepotrzebną biurokrację, która nas spowalnia. Poprosiłem ET, aby spojrzeli na swoje organizacje świeżym okiem, skupiając się na usuwaniu warstw, zwiększaniu zakresu kontroli i wzmacnianiu pozycji najlepszych wykonawców. Nasi konkurenci są szczupli, szybcy i zwinni — i tacy właśnie musimy się stać, aby poprawić nasze wykonanie. Byłem zaskoczony, gdy dowiedziałem się, że w ostatnich latach najważniejszym KPI dla wielu menedżerów w firmie Intel była wielkość ich zespołów. W przyszłości tak nie będzie. Wierzę w filozofię, że najlepsi liderzy osiągają najwięcej, angażując jak najmniej osób. Przyjmiemy ten sposób myślenia w całej firmie, co będzie obejmować umożliwienie naszym najlepszym talentom podejmowania decyzji i przejmowania większej odpowiedzialności za kluczowe priorytety. Nie da się obejść faktu, że te krytyczne zmiany zmniejszą liczebność naszej siły roboczej. Jak powiedziałem, gdy dołączyłem, musimy podjąć kilka bardzo trudnych decyzji, aby postawić naszą firmę na solidnych podstawach na przyszłość. Rozpocznie się to w Q2 i będziemy działać tak szybko, jak to możliwe w ciągu najbliższych kilku miesięcy. Będziemy bardzo świadomi tego, gdzie skupimy te wysiłki i jak wypadniemy w porównaniu z najlepszymi w branży. Wyciągnęliśmy kilka cennych wniosków z poprzednich działań. Musimy zrównoważyć nasze redukcje z potrzebą zatrzymania i rekrutacji kluczowych talentów. Upoważnię każdego z moich liderów do podejmowania najlepszych możliwych decyzji zgodnych z naszymi najważniejszymi priorytetami. Decyzje te nie będą podejmowane lekkomyślnie i będziemy Cię regularnie informować." Całość tutaj: https://www-intc-com.translate.goog/news-events/press-releases/detail/1738/lip-bu-tan-our-path-forward?_x_tr_sl=en&_x_tr_tl=pl&_x_tr_hl=pl&_x_tr_pto=sc
-
Istnieje pewne wyjaśnienie słabego L3 w ArrowLake. W wywiadzie dla Kitguru potwierdzono, że zespół P-Core pracował tylko nad rdzeniem LionCove oraz pamięciami podręcznymi L0, L1 i L2. Pamięć podręczna L3 została zaprojektowana przez inny zespół. "Podobno" PantherLake ma to naprawić a NovaLake udoskonalić. "Czekaj TM".
-
Niech najpierw naprawią pamięć podręczną L3, zanim zaczną dodawać jej więcej, na wzór X3D. Zen5 L3 48 cykli (8.44 ns) 1T: 173.6 GB/s nT: 1.6 TB/s LionCove L3 84 cykle (14.83 ns) 1T: 57 GB/s !!!!MA-SA-KRA!!!!! (Zen5 L3 dla 1T ma 3x większą przepustowość!) nT: 1.02 TB/s L3 w ArrowLake to już chyba bardziej skopać się nie dało. Gratulacje dla "sabotażysty"/"wybitnego(inaczej) inżyniera"(niepotrzebne skreślić).
-
Fizycznie był już w SunnyCove, GoldenCove i być może jest w LionCove, ale nieaktywny. W NovaLake ma być aktywny dla P i zaimplementowany w e Core. Spekuluje się, że e Core ArcticWolf ma wykonywać 512-bit, używając podwójnych jednostek 256-bitowych, jak w Zen4. CoyoteCove ma pełne jednostki 512-bitowe. Edit: "14900k nie jest szybszy, 285k jest lepszym wyborem, ponieważ działa chłodniej, jest wydajniejszy, a podkręcanie jest o wiele bardziej stabilne w dłuższej perspektywie. Po prostu nie warto go ulepszać w porównaniu do 14900k, jest bardziej dla osób, które chcą dokonać ulepszenia i używają procesora 11. generacji lub starszego." https://www-overclock-net.translate.goog/threads/overclocking-arrow-lake-285k-265k-245k-etc-results-bins-and-discussion.1811860/page-424?post_id=29445768&_x_tr_sl=en&_x_tr_tl=pl&_x_tr_hl=pl&_x_tr_pto=sc#post-29445768 "Arrow Lake to ZDECYDOWANA poprawa (jeśli udajemy, że Zen 5 X3D nie istnieje ). Jest jeszcze nadzieja dla Intela!" "ARL to z pewnością ulepszenie, które jest hamowane przez powolny L3 i słabą tkaninę die to die" https://forums-anandtech-com.translate.goog/threads/intel-meteor-arrow-lunar-panther-lakes-discussion-threads.2606448/page-766?_x_tr_sl=en&_x_tr_tl=pl&_x_tr_hl=pl&_x_tr_pto=sc#posts
-
Coyote Cove i Arctic Wolf mają podobno mieć zaimplementowany APX(nowe 64bit z 32 zamiast 16 rejestrami) i AVX512. https://www-phoronix-com.translate.goog/news/Intel-AVX10-Drops-256-Bit?_x_tr_sl=en&_x_tr_tl=pl&_x_tr_hl=pl&_x_tr_pto=sc NovaLake do 52 rdzeni czyli 16P + 32e + 4e w IOD.
-
"Tak Polskę potraktowały USA. Trafiliśmy do gorszej kategorii krajów" https://www.money.pl/gospodarka/tak-polske-potraktowaly-usa-trafilismy-do-gorszej-kategorii-krajow-7114240392719072a.html
-
"Analiza podsystemu pamięci Lion Cove w Arrow Lake" https://chipsandcheese-com.translate.goog/p/analyzing-lion-coves-memory-subsystem?triedRedirect=true&_x_tr_sl=en&_x_tr_tl=pl&_x_tr_hl=pl&_x_tr_pto=sc&_x_tr_hist=true