AMDK11
-
Postów
115 -
Dołączył
-
Ostatnia wizyta
Treść opublikowana przez AMDK11
-
Ale tylko w mobile. W desktop Zen5 czy trochę wolniejszy, na równi czy trochę szybszy zależnie od tytułu jest zawsze możliwość wymiany na X3D który nie ma sobie równych :)
-
Przepraszam, panowie. Myliłem się. Zen5 ma dekoder 2x4-Wide, ale dla ST może osiągnąć max 4-Wide. Pamięć podręczna mikrooperacji ma 12-Wide(2x6-Wide) nawet dla ST(wcześniej na forach sugerowano że dla ST dostępne jest 6-Wide). Zen5 dla ST może osiągnąć szczyt 7-8 IPC a typowo 5-6 IPC (Zen4 osiąga szczyt 5-6 IPC(warunki laboratoryjne)). Jak napisał Agner Fog, Zen5 to znacząca różnica i nowy poziom przepustowości. SMT faktycznie potrafi wycisnąć 7-8 IPC z Zen5.
-
Racja. 18 potoków LionCove są na TSMC N3B a 18 potoków CougarCove są na Intel 18A
-
Nie ma to jak chwalenie się 18 potokami wykonawczymi w CougarCove, skoro LionCove ma to samo
-
Noctua wchodzi w AiO
AMDK11 odpowiedział(a) na trepek temat w Chłodzenie, obudowy, zasilacze i modyfikacje
Bo ma działać jak każdy inny komponent. Czy ktoś ocenia estetykę elektroniki monitorów EIZO? Raczej nie, bo estetyka jest podporządkowana funkcjonalności, a nie odwrotnie. Tak to widzę, a przynajmniej tak mogłoby być, gdyby specyfikacja była dobra, a urządzenie wydajne. Kupując komponent, chcę, żeby dobrze działał, a nie zachwycał wyglądem. Zawsze mi się podobała, zwłaszcza że Noctua nie da się pomylić z żadną inną marką. Chłodzenia i wentylatory od Noctua zawsze sprawowały się świetnie. Co do wyglądu to są gusta i guściki. -
Z mojej analizy wynika, że jeśli zależy Ci na żywotności i stabilności procesora, najlepiej pozostawić pamięć RAM DDR5 na ustawieniach fabrycznych procesora(np 5600 2x16GB). Wszystko powyżej tych ustawień na GraniteRidge oznacza podkręcanie (OC) i wyższe napięcia. Co skraca żywotność o 10%(nawet przy minimalnym OC). Im wyższe napięcie tym krótsza żywotność dla 1-5+%((DDR5 6000) zależnie od testu) wyższej wydajności.
-
Ciekawostka: AMD oficjalnie podaje że implementacja SMT w rdzeniu Zen4 i Zen5 zajmuje mniej niż 5%.
-
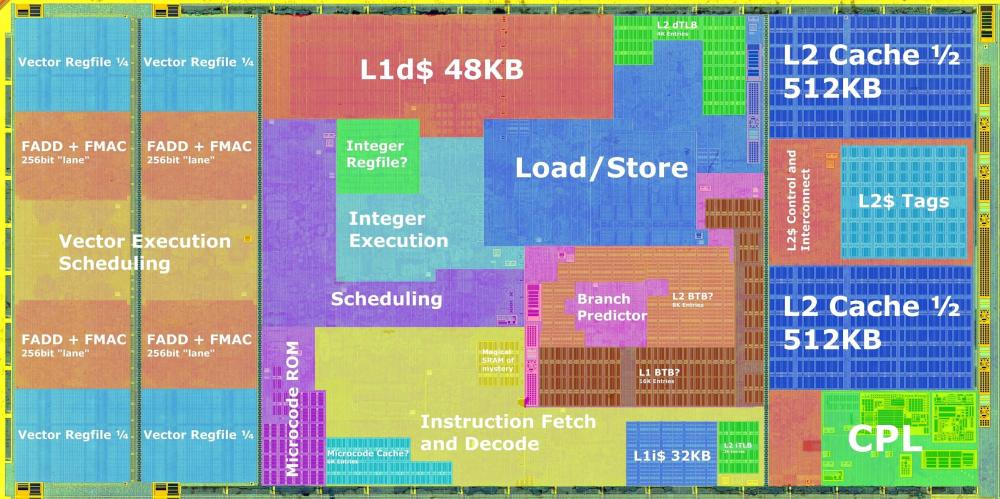
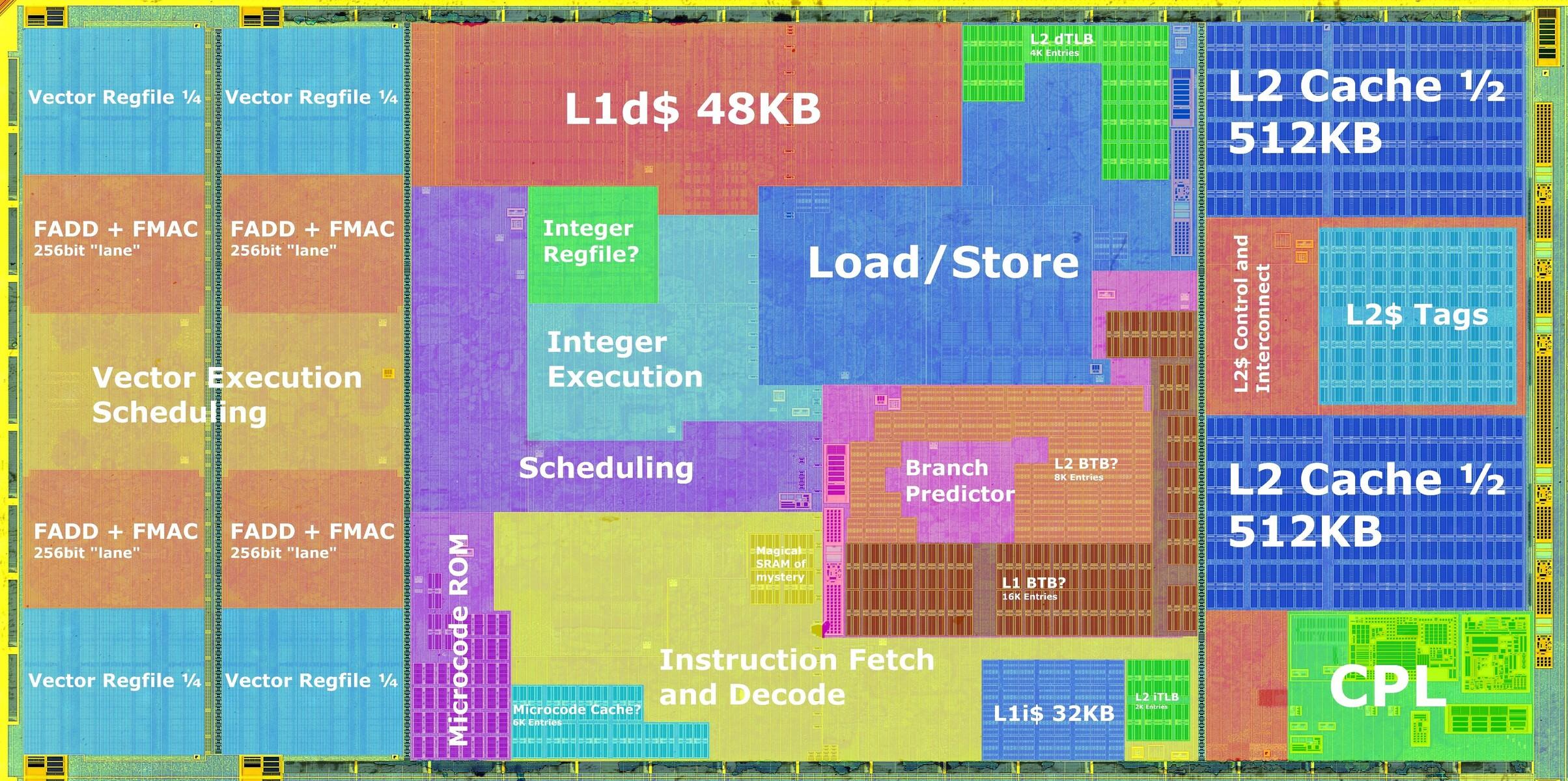
Użyłbym mocniejszego zasilacza, zwłaszcza w pierwszym przypadku, nawet biorąc pod uwagę brak dedykowanej karty graficznej. Zwłaszcza jeśli system jest używany do pracy i działa przez większość czasu. Edit: Mam kolejną ciekawostkę co do Front-End po długiej analizie Zen5: Zen5 ma pobieranie 2x 32Bajty na cykl z L1-I 32KB 8-Way (Zen 4 ma 1x 32Bajty), Dekoder 2x 4-Wide (Zen4 1x 4-Wide), OP-Cache 2x 6uops na cykl(Zen4 1x 9uops) i okazuje się że Zen5 może dla: ST: 32Bajty z L1-I, dekoder 1x 4-Wide i OP-Cache 1x 6uops SMT: 64Bajty z L1-I, dekoder 8-Wide i OP-Cache 12uops Za to dla ST i SMT jest: 6ALU(Zen4 4ALU), 4AGU(Zen4 3AGU), 4FP+2StoreFP(Zen4 3FP+2StoreFP) i ścieżki FP 512b (Zen4 ścieżki FP 256bit). Mimo klastrowego front-endu Zen5, scheduler Integr jest zunifikowany dla 6ALU i to poraz pierwszy w historii AMD. Wcześniejsze generacje do Zen4 każdy z portów ALU miał osobny scheduler. Teraz Zen5 ma jeden dla wszystkich 6ALU co jest optymalne dla ST, ale bardziej skomplikowane. Dobrą rzeczą jest to, że bardzo zaawansowany i rozbudowany nowy predyktor, który przewiduje dwie kolejne gałęzie z 3 otwartymi oknami, długimi i skomplikowanymi wzorcami oraz ogromnym BTB 24K, działa zarówno w trybach ST, jak i SMT. Mimo to średni wzrost IPC dla Zen5 wynosi +16% (średnia +14% dla INT i średnia +24% dla FP). Średnia wzrostu IPC dla Zen5 w porównaniu do Zen2 wynosi +49%, w porównaniu do Zen1 +66%, w porównaniu do Excavatora +117%, a w porównaniu do Bulldozera to już 140-150%. Do tego znacznie wyższe taktowanie Zen5 i różnica jest jeszcze większa. Jestem ciekawy czy Zen6 poprawi wykorzystanie obu klastrów w ST.
-
Mam właśnie chłodzenie Noctua na AM5 dla R5 9600X i mocowanie tej chłodnicy wygląda jak to na tym ASUSie. Mogę to potwierdzić w 100%.


-
Od dluższego czasu zostawiam na ustawieniach fabrycznych, bez kombinowania o każdy % wydajności. Czy te upalone były poddane OC?
-
Stary BIOS z zeszłego roku.
-
Ciekawostka: Zen 4 (Raphael) typowo (real-world, mieszany kod): ~3–4 instrukcje/cykl. sustained µops (dobry tight loop / op-cache): ~5–6 µops/cykl w praktyce; op-cache nominalnie może dostarczyć do 9 µops/cykl (teoretyczny peak). chipsandcheese.comnumberworld.org maksymalny syntetyczny szczyt: rzadko ~6 instr/cyc (laboratoryjne scenariusze). Zen 5 (Nirvana / Granite Ridge) typowo (real-world, mieszany kod): ~5–6 instrukcji/cykl (Agner: „potrafi dostarczać 6 instr/cyc w wielu przypadkach”). agner.orgchipsandcheese.com sustained µops (op-cache): w praktyce około 6 µops/cykl średnio (op-cache nominalnie 12 µops/cykl, ale nie jest w pełni wykorzystywany w większości kodu). chipsandcheese.com+1 maksymalny syntetyczny szczyt: 6 instr/cyc typowo, w idealnych mikrobenchach rzadko do ~8 instr/cyc (Agner). agner.org
-
Ciekawostka: Zen 4 (Raphael) typowo (real-world, mieszany kod): ~3–4 instrukcje/cykl. sustained µops (dobry tight loop / op-cache): ~5–6 µops/cykl w praktyce; op-cache nominalnie może dostarczyć do 9 µops/cykl (teoretyczny peak). chipsandcheese.comnumberworld.org maksymalny syntetyczny szczyt: rzadko ~6 instr/cyc (laboratoryjne scenariusze). Zen 5 (Nirvana / Granite Ridge) typowo (real-world, mieszany kod): ~5–6 instrukcji/cykl (Agner: „potrafi dostarczać 6 instr/cyc w wielu przypadkach”). agner.orgchipsandcheese.com sustained µops (op-cache): w praktyce około 6 µops/cykl średnio (op-cache nominalnie 12 µops/cykl, ale nie jest w pełni wykorzystywany w większości kodu). chipsandcheese.com+1 maksymalny syntetyczny szczyt: 6 instr/cyc typowo, w idealnych mikrobenchach rzadko do ~8 instr/cyc (Agner). agner.org
-
Cytat z forum Anandtech: https://forums-anandtech-com.translate.goog/threads/thought-leadership-amd-vision-removed-official-amd-presentation.2631672/?_x_tr_sl=en&_x_tr_tl=pl&_x_tr_hl=pl&_x_tr_pto=sc
-
Może ASUS też pójdzie tą drogą.
-
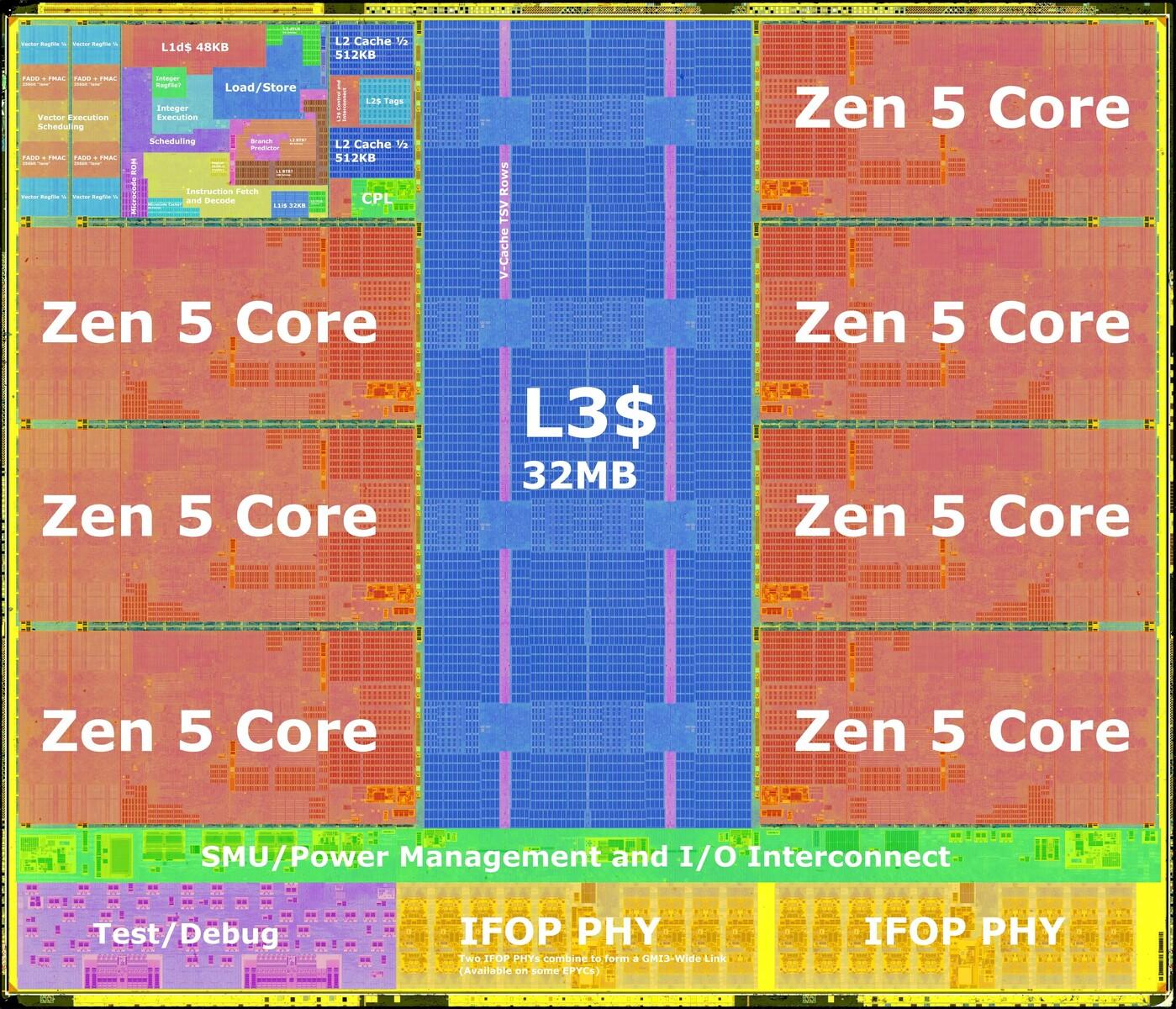
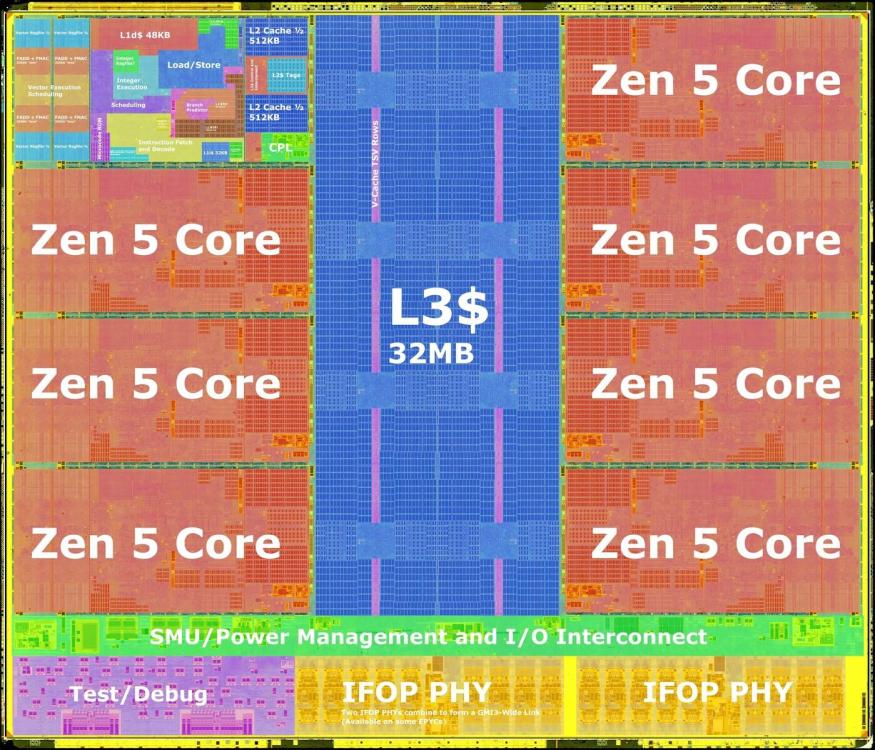
Zamieściłem ten cytat na poprzedniej stronie, ale pozwólcie, że powtórzę. Podsumowanie mikroarchitektury Zen5 po naukowej analizie: Quantifying The AVX-512 Performance Impact With AMD Zen 5 - Ryzen 9 9950X Benchmarks https://www.phoronix.com/review/amd-zen5-avx-512-9950x/2 When taking the geometric mean of the 90 benchmarks used for this AVX-512 on/off comparison, the Zen 5 AVX-512 implementation with the Ryzen 9 9950X saw its performance go up by 56% while the Ryzen 9 7950X Zen 4 with its "double pumped" AVX-512 implementation saw its performance go up by 41%. Zen 4's AVX-512 was great and now with Zen 5 it's even better with the SKUs having the full 512-bit data-path. This is especially good news for Ryzen 9000 series (EPYC 4005?), EPYC Turin, etc. Rdzeń Zen5: Po lewej, te dwie pionowe struktury to FPU(SIMD+Vector) i ogromna ilość logiki dla AVX512. Ogólnie rzecz biorąc, rdzeń Zen5 + L2 jest ogromny(ilość tranzystorów w logice). 8 rdzeni Zen5 CCD: ArrowLake 8 rdzeni LionCove + 16 Skymont:
@Zen5@Granite_Ridge@Ryzen_5_9600X@100-000001405_BY_2429SUY_9AEQ579S40073_DSCx14_CCD_poly@5xExt.thumb.jpg.a772a42ee7977e6ebc12302fe084455f.jpg)
.thumb.jpg.4e270c73233b018ec6fa0d5c415663bc.jpg)

-
Chodziło o same rdzenie x86 Zen5 + L3. Edit: Szczegółowa analiza Zen5 autorstwa Agnera Foga: https://www-agner-org.translate.goog/forum/viewtopic.php?t=287&start=10&_x_tr_sl=en&_x_tr_tl=pl&_x_tr_hl=pl&_x_tr_pto=sc Szczegóły naukowej analizy różnych mikroarchitektur Intel, AMD i Via w formie PDF: https://www.agner.org/optimize/microarchitecture.pdf#[{"num"%3A46%2C"gen"%3A0}%2C{"name"%3A"XYZ"}%2C87%2C704%2C0] Potwierdza to, co pisałem wcześniej o najnowocześniejszym i najpotężniejszym rdzeniu x86, jakim jest Zen5
-
Czy wiecie, że Zen5 to całkowita przebudowa i rozbudowa rdzenia? Zen5 to sprytnie i przemyślanie zaprojektowany rdzeń. LionCove to nakoksowany pustak w porównaniu z Zen5. Zen5 to najbardziej zaawansowany i sprytny rdzeń x86.
-
Ciekawostka: Rdzeń Zen5 został przebudowany i znacząco poszerzono w nim logikę o 26% w porównaniu z Zen4, a ilość tranzystorów wzrosła o 218 milionów! Dla porównania, zmiany w pojedynczym rdzeniu Zen5 zajęły tyle samo tranzystorów, co cały rdzeń Skylake, składający się z 217 milionów tranzystorów! Głównym celem Zen5 było znaczące poszerzenie struktur rdzenia, co wiąże się z przeprojektowaniem i nową logiką sterowania. Myślę, że Zen6 i Zen7 zostaną minimalnie rozbudowane i w dużej mierze zoptymalizowane, podobnie jak Zen3.
-
Tak naprawdę nie ma znaczenia, czy bazą jest E czy P, bo ostatecznie będzie to po prostu rdzeń P, prawdopodobnie zawierający najlepsze cechy obu "światów"
-
Skoncentrują się na jednym typie rdzenia, co prawdopodobnie jest dobrym posunięciem, gdyż jest znacznie tańsze w utrzymaniu i lepsze w rozwoju.
-
Na razie nic nie jest pewne i dopóki dane te nie zostaną zweryfikowane, pozostają one jedynie spekulacjami, do których należy podchodzić z dystansem. Co do Zen6 jestem bardzo dobrej myśli
-
Wątpię, ale kto wie.
-
Instruction Per Cycle(IPC). Inaczej "Instrukcje na Cykl" zegarowy procesora.
-
Gry osiągają średnio 1-2 IPC, podczas gdy Zen5 i LionCove osiągają 8(szczytowo więcej dzięki UOP Cache). W grach lepiej jest mieć najniższe możliwe opóźnienie i najwyższą możliwą częstotliwość taktowania. Opóźnienie jest znacznie redukowane dzięki dużym pamięciom podręcznym, takim jak 3D V-Cache AMD i samą logiką sterującą rdzenia obliczeniowego.



@Zen5@Granite_Ridge@Ryzen_5_9600X@100-000001405_BY_2429SUY_9AEQ579S40073_DSCx14_CCD_poly@5xExt.jpg.8ac7523ce71dd8424f7e6654bb9acc3d.jpg)
.jpg.236e1f4d7a81028e6b49adec33a94715.jpg)