


musichunter1x
-
Postów
2 649 -
Dołączył
-
Ostatnia wizyta
Treść opublikowana przez musichunter1x
-
Kojimę już zalała polska fala komentarzy

-

Mały komputer gamingowy - czy coś takiego istnieje ?
musichunter1x odpowiedział(a) na Barosz temat w Zestawy komputerowe
Zdecydowanie lepszy, jeśli nie zależy Ci na przenoszeniu i zintegrowany ekranie, bo laptopa dużo trudniej schłodzić. Jeśli nie chcesz dłubać samemu, to lepiej złóż to, co będziesz chciał czyścić, bo prędzej czy później czeka Cię to. -
Znalazłem przypadkiem, szukając "Elden Ring Chicken" Czuć trochę Heavenly Sword i może jakieś Warriors od Nintendo.

-
Mały komputer gamingowy - czy coś takiego istnieje ?
musichunter1x odpowiedział(a) na Barosz temat w Zestawy komputerowe
Określ co znaczy dla Ciebie "mała obudowa". 4L, 10L, 15L, 20L litrów objętości? W <14L bez problemu można wsadzić jakiegoś rtx5070 / rx9070 i dowolny CPU, bo w grach i tak 65W wystarczy na nim, przy rozsądnej ciszy i bez tony kombinowania, ale na mniejszy komponentach. Najmniejsza buda ma ~4L -Jonsbo NV10, wielkość przyszłego GabeCube, gdzie wejdzie rtx4060 / 5060, ale będzie głośno, przez mocne upakowanie i low profile. Deepcool CH260 z linku wyżej nie jest mała. To ma aż 30 litrów. Już nawet rtx5060 ma większą moc, ale brakuje Vramu, więc możesz wybrać dowolny rozmiar, jeśli Ci to nie przeszkadza. RTX5070 Asus Dual wejdzie do wielu małych obudów, bo ma tylko 250mm. Jonsbo C6 Black zmieści ją, ale również płytę matx oraz zasilacz atx, tylko chłodzenie procesora trzeba zmienić i najlepiej mieć modularny zasilacz. Tylko ~16L na pełnowymiarowe komponenty, bez risera... https://www.jonsbo.com/en/products/C6.html Edit. Tylko że wersje Dual "Evo" będą raczej lepiej chłodzić kartę w takiej obudowie przez układ finów. Takie wersją są wśród rtx4070, 4070super oraz rtx4060ti, rtx5060, 5060ti, bez dopisków Evo. -
Kolejne teoria jest taka, że to były konta dla dzieci, które tam ściągał. A z innych rzeczy... Bardzo niepokojący jest kod Jerky, który sugerowałby że jeszcze jedli ludzkie mięso... Gdzie indziej przypomniano mi jeszcze o filmie "Eyes Wide Shut", gdzie reżyser chyba był na liście Epsteina, a film bardzo mu pocięli i nie chcieli dopuścić wersji oryginalnej. Nawet jego narratora nie wstawili. Umarł na zawał parę dni po pierwszym, wewnętrznym pokazie i wycięto ~40 minut filmu. Teoria jest taka że ciążył mu temat i próbował to jakoś przedstawić we filmie, ale to wszystko to praktycznie z plotek zebrałem. Na podcaście z człowiekiem od jakiś służb specjalnych słyszałem, że zawał można bardzo prosto wywołać, ponoć wystarczy wstrzyknąć kofeinę... Jednak parę rzeczy się nie klei.
-
[KartoGraficzny Offtop] - wątek do luźnej dyskusji o wszystkim co dotyczy GPU
musichunter1x odpowiedział(a) na cichy45 temat w Karty graficzne
Brakuje jeszcze tylko końcówki z użytkownikiem - Ray Lagging lub Frame Trashing
-
Kusicie offtopem do telefonów, ale nie rozpiszę się Kiedyś nawet redmi 3s "zasuwało", a wymiana baterii to było kilka zatrzasków, a tam było pewnie 2gb ramu.
-
Sam nie wiem, może informacje nawet nie są dostępne. Natomiast jest to prosta logika... Produkcji nie można łatwo zwiększyć w znacznym stopniu, a zapotrzebowanie od firm strzeliło w kosmos. Firmy mogą płacić znacznie więcej, ponieważ to "inwestycja". Gdyby utrzymać niskie ceny to kto inny podkupi sprzęt i sprzeda innemu drożej... Tak działa handel od prehistorii... Przenosisz towar z rejonu o niskim zapotrzebowaniu tam, gdzie występują braki, dzięki czemu masz większą marżę. Normalnie firmy dwoiłyby się żeby zwiększyć produkcję, ale proces produkcji jest skomplikowany oraz dochodzi zmowa cenowa, bo nie chcą sprzedawać więcej po niższej cenie, a potem zostać z nadmiarem w razie spadku sprzedaży. Przed tym szaleństwem nawet zmniejszali produkcję, bo było za dużo pamięci na rynku, stąd takie spadki cen <400 zł za 32gb dobrego ramu.
-
Produkcja może kosztować nawet tyle samo, ale mają ograniczoną dostępność. Wolą wyprodukować ram dla firm od AI itp. sprzedając wielokrotnie drożej, niż konsumencki w niskiej cenie... Aby dalej ktoś chciał produkować zwykły ram to podnoszą ceny, bo inaczej poszłoby do AI, tak jak odział Samsunga nie chciał sprzedać pamięci do działu telefonów, bo mogą sprzedać drożej na zewnątrz.
-
Galeria, ciekawostki miniPC ITX mATX
musichunter1x odpowiedział(a) na Keel temat w Chłodzenie, obudowy, zasilacze i modyfikacje
W 2011 ktoś wpadł na taki pomysł, a dziś próżno szukać Wystarczy wywalić klatki montażowe, wentyl 140mm na front jako wydmuch, tył zaciąga dla CPU, skrócić to do matax i schłodzi 200-250W w ciszy...(Edit. Jednak schłodziłoby pewnie nawet 360W na Gpu w ciszy.) A kto inny zrobił coś takiego z Nano S, wystarczy wykonać coś podobnego w oryginale pod PSU ATX, lekko nad płytą. Przestaje mnie bawić projekt w Metis Plus, bo jednak filtry od góry dla GPU to kiepski pomysł. Kurz zbierają jak głupie, a drobny jest przesiany do środka, bo grawitacja robi swoje. Teraz od biurka powstaje rezonas przez GPU, ale gdy jestem naprzeciwko budy to nie słychać Może coś z matami pokombinuję. Spokojnie można by wsadzić Asus dual rtx5070 po UV do ~200W, po odpowiednich modyfikacjach i odwróceniu wentylatora w PSU. RTX3060ti przy 200W daje radę schłodzić nawet bez przesady z hałasem, a 188W w przyzwoitych warunkach, ale muszę rozwiązać ten rezonans w zabudowie.

-
Przy tak wielkich budach mogliby montować zasilacz na froncie, na dole i kabel zasilający wyprowadzić na tył... GPU miałoby bezpośredni dostęp do powietrza.
-
Szkoda nawet coś pisać, po prostu jest to Concord 4. Concord, Highguard, Marathon, to coś... Ktoś znowu uderzył się w głowę i zapomniał że gry to przede wszystkim gameplay i atmosfera, a nie "the message" oraz komfortowa papka i zbiór popularnych dupereli, w tym styl Fortnite. Pewnie z połowa pracowników nie dba o dobrą grę, tylko żeby nikt nie był pokrzywdzony, a HR nadrabia parytety, zabijając szansę na wewnętrzną krytykę, toksyczną pozytywnością... Oh, ale pewnie ktoś z góry ustalił zbiór cech gry i kazał zrobić coś takiego. Niewielu chciało przy tym pracować, więc znowu prościej o marnych pracowników, którzy nie postawią się durnym pomysłom, przynajmniej takie mam przypuszczenia. Zabijcie to zanim złoży jaja. Wrócę gdy nagrają parodię z tego.
-
Jedna z ostatnich, dobrych rzeczy jakie zrodzi ta gra. Na to czekałem
-
RE prawie zawsze polegał m.in. na optymalizowaniu tras i podnoszenia przedmiotów w takim momencie, aby robić to sprawnie. Co innego, że akcyjne odsłony oraz od czasów Village tego praktycznie już nie ma. Element zarządzania, a marne wymuszone powroty zawsze w ten sam sposób to nie to samo.
-
Eh, tylko nie zwróciłeś uwagi że DLSS 4.5 używa FP8 co zmniejsza wielkość danych, ale w sumie nie da rady inaczej, bo na Ada nawet preset K działa w FP8. Dopiero preset L używa więcej parametrów, ale musiałbym sprawdzić, które są "trwałe", bo moje początkowe teoretyzowania nie rozróżniały tego. W skrócie - moje dumania były błędne, ale z innego powodu niż sugerowaliście... No jeszcze kompletnie błędne było założenie, że znacznie więcej elementów może korzystać z "L2 persistance". Już wspomniałem w poprzednim komentarzu, że przesadziłem z szacunkami użycia cache, bo niewiele rzeczy używa trybu "trwałego", nawet w DLSS Transformer są to głównie 2 elementy. Na 48MB nie przekroczysz tego, może nawet na 32MB przy FP8. Więc moje początkowe założenia były rozdmuchane i w sumie trzebaby czekać ma kolejną wersję DLSS z jeszcze większą objętością elementów w "trwałym L2". Ewentualnie możnaby testować na Ampere preset K, ale tam i tak zawsze przekroczy cache przez co nawet nie spróbuje załadować na stałe tych 2 elementów, które w CNN były znacznie mniejsze. Edit. No i te piękne dane z testu niestety raczej nie pokazują ile cache wydzielono jako "persistent L2", ale dziękuję za zaangażowanie. Może jeszcze są tam dodatkowo informacje? Edit.2 Potem spróbuję poszukać czy coś jeszcze zauważalnie korzysta z L2 persistence. Wcześniej wkleiłem tylko listę przykładowych elementów mielonych przez cache i już nie dziwię się skąd wasze oburzenie, bo rzeczywiście tam raczej wszystko lub większość używa cache w klasycznym sposób. Jedynie "trwały L2" ogranicza pulę wolnego L2 dla reszty.
-
Tylko że mówię typowo o L2, a ta funkcja jest używa właśnie przy DLSS. Jedynie wcześniej przesadziłem z szacunkami użycia cache, bo malo co korzysta z "trwałego" trybu L2 i prawie wszystko działa tak, jak argumentowaliście w tym wątku.
-
Mogę głównie przy pomocy AI próbować coś wygrzebać, bo z pamięci to niewiele wygrzebię. Na pewno wagi modelu i parametry sieci są zapisane jako "Persisting", jedno to 2-4MB drugie ~1MB. Wektory ruchu itp. rzeczy z bufora klatki ciągle zmieniają się, więc tego należałoby nie liczyć, ale nadal musi przejść przez cache w odpowiednim momencie... ALE, właśnie CNN miało ponoć "wagi statyczne", Transformer posiada jeszcze "mapy uwagi" - Attention Maps, a same wagi są większe. Najlepiej, aby oba miały przypisany, trwały L2, gdzie AI szacuje to na 18-24MB + 6-10MB = 24-34MB, dla samych Model Weights oraz Attention Maps. Użycie RR trochę dodaje MB do obu. Wystarczy mi tematu na dziś. Edit. Tylko dodam, że FP8 powinno zmniejszyć to o połowę lub coś zbliżonego. Edit.2 Jeszcze wróciłem sprawdzić co powie w przypadku gddr6x rtx3060ti, bo przepustowość powinna trochę nadrobić braki cache. Wypluła coś takiego względem CNN, szacunki dla 1440p, chyba quality... Dla Performance wypluło już 1-3% dla gddr6x, względem gddr6 5-8%.
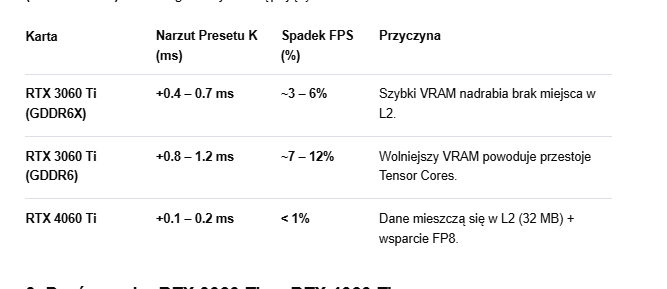
-
Nvidia niby chwali się, że skutecznie upycha pewne dane do cache... Deweloperzy od czasów Ampere mogę wydzielać fragment L2, aby był "trwalszy" choćby dla jakiś kluczowych danych DLSS. Rozchodzi mi się o wielkość takich danych, które są tam upychane przy pomocy L2 Persistence, dodanym w Residency Control. Stąd mój logiczny wniosek, że jeśli karta nie zmieści elementów, które skorzystałyby z trwałego L2 to musi być jakiś przestój. Mogę mylić się co do wielkości tych danych, bo to próbowałem oszacować przy pomocy AI. Szkoda że dopiero teraz doprecyzowałem swoją tezę
-
Dobra, sam zmęczyłem się tą rozmową, a uciekło już meritum... Więc powtórzę sedno: Skupiam się na kwestii opóźnienia wywołania danych z Vram, gdy akurat nie ma potrzebnych danych w cache, bo nie zdążyło ich przerzucić lub całość nie mieści się na raz. Dawniej karty skupiały się na intensywnym mieleniu danych, szybko zastępując cache następną porcją, aby jak najszybciej wykarmić rdzenie. Teraz mogą zarezerwować fragment cache pod daną strukturę danych, aby zawsze była na miejscu, gdy jest potrzebna, bez czekania na wywołanie Vramu i przesłanie tego dalej... Dlatego wspominam L2 Cache Residency Control. Również więcej elementów może być wywołanych "bezpośrednio" z Vramu, co zrobiło miejsce na inne elementy..., a raczej zwiększyło skuteczność upakowania danych bez przestoi. Dlatego wspomniałem o usprawnionym asynchronous compute w Ampere, które pozwala pominąć rejestr, kopiując dane w tle. Rzucając tymi szacunkami użycia cache przez DLSS chciałem, aby ktoś zweryfikował w jakim stopniu zużycie pokrywa się z rzeczywistością... Nie dostałem żadnych informacji ile danych ładują katy do cache na rzecz DLSS, tylko ciągle przypomnienia "jak działa cache", gdy cały czas chodzi mi o redukcje przestojów przez umieszczenie danych w cache na czas...
-
Nie no Tomcug, ty też. Przecież ja nie mówię że zwiększenie cache to rozwiązanie na wszystko i boost wydajności, tylko że gdy zabraknie cache na zamieszczenie konkretnych, potrzebnych danych w konkretnym momencie to powstanie przestój. Nawet wyżej podałem funkcję, która może przyczynić się do lepszego zarządzania cache przez Ampere - L2 Cache Residency Control. W tym co podałeś nie ma nic o tym, ile zajmują elementy z bufora poprzedniej klatki itp. Na dodatek Ampere wprowadziło sprawniejsze "asynchronous compute" co m.in. trochę odciążyło cache. To wszystko właśnie służy minimalizowaniu przestojów...
-
@SebastianFMPrzecież nie o tej podstawie jest dyskusja... Tak, przetwarzane jest małymi fragmentami, sam to wspominam i nie wiem po co w innym komentarzu pisałeś o całym pliku DLSS, gdy chodziło mi o przechowywanie elementów z poprzedniej klatki w cache. Od Ampere mogą decydować o zarządzaniu danymi w cache, bez poleganiu na samej automatyce układu. CNN miało właśnie mniejsze fragmenty, transformer stara się patrzeć "całościowo" na piksele, stąd większy rozmiar danych, któe mogą skorzystać z niskich opóźnień. Tak, dane są ładowane do cache na bieżąco, "rozłożone w czasie"... Chodzi właśnie o redukcje przestojów przez poprawę zarządzania tym, co ma się znaleźć w L2 i zapobiegnięciu usunięciu potrzebnych danych przy ładowaniu kolejnych. Pewne dane skorzystają na planowanym umieszczeniu w cache dzięki niższym opóźnieniom... Właśnie na tym zyskuje m.in. DLSS oraz RT. Serio niektórzy nie rozumieją, że od Ampere trochę zmieniło się, gdzie Ada umożliwiła ciekawszą utylizację L2 przez większy rozmiar... Developerzy mogą tego nie optymalizować, skoro konsole nadal siedzą na paru MB. Edit. Sam już nie wiem, kto jest tu ignorantem ja czy reszta. To o czym mówię jest możliwe od czasu wprowadzenia m.in. L2 Cache Residency Control. Od tamtego czasu GPU nie używa cache tylko jako strumienia, teraz może być wydzielone "trwałe" miejsce na dane, które skorzystają na trochę dłuższej obecności lub zagwarantowanym miejscu. Piszecie tak, jakby to było niemożliwe. @sidebandMógłbyś odnieść się do L2 Cache Residency Control? Na dodatek powtórzę - nie zrozumieliśmy się w przypadku "wspólnego L2". Przecież nie chodzi o fizyczne położenie L2, lecz o wspólne adresowanie danych dla "wszystkich rdzeni". W CPU są oddzielne dla każdego rdzenia, w GPU tak nie jest.
-
Ale ja to wiem... Chyba ciągle obracasz się w czasach sprzed Ampere, gdzie wprowadzili L2 Cache Residency Control. Chodzi o to, że obecnie jest tak używany do niektórych danych, bo można wcześniej zaplanować jakie będą potrzebne... Zamiast czekać aż karta będzie potrzebowała np. elementów bufora z poprzedniej klatki, to można załadować je tuż wcześniej, w odpowiednim momencie lub po prostu zadbać by miało miejsce / zapobiec ich usunięciu z cache. Tak to karta sprawdziłaby czy jest w L1, L2 i wydała żądanie o przesłanie z Vramu, co spowodowałoby mały przestój przez czekanie na dużo wolniejszy Vram... Edit. Serio już myślałem że pogubiłem się przy sprawdzaniu tematu, ale po prostu nie rozumiecie co mam na myśli, bo ciągle mówicie o funkcji cache sprzed Ampere... Teraz przynajmniej mam przypuszczenie co do kolejnego elementu przyczyniającego się do gorszej wydajność m.in. DLSS na Turing.
-
Dla mnie cache to po części taki odpowiednik kondensatora, ale mam wrażenie że kompletnie pomijasz większą ilość i wagę elementów które obecnie tam trafiają... Karta doładuje sobie potrzebne dane z Vramu, ale problemem są opóźnienia. Ada usprawniła również zarządzanie wymianą tych danych... Nie skupiasz się przypadkiem na samej roli cache jako ""kondensatora", nie biorąc pod uwagę jakie elementy tam trafiają i co się dzieje gdy nie są tam w całości lub na czas? Bo nie musi mieć 2 razy wiekszego cache? Przecież nie to argumentuję... Z czym się tutaj kłócisz, bo sam już nie wiem... Jeśli cache nie starcza na raz to GPU czeka aż Vram dośle potrzebne rzeczy i wtedy jest mały przestój o ten czas potrzebny na dosłanie. Nvidia mogła tak dobrać przypadek testowy, by nigdy nie przekroczyło, aby mieć czyste dane o mocy obliczeniowej.
-
? Ale rozumiesz że FPS nie skaluje się liniowo z cache? Jeśli potrzebne dane mieszczą się to nie ma dodatkowych opóźnień wynikających z czekania na Vram. Jeśli cache wystarcza to wydajność zależy tylko od mocy obliczeniowej, a wątpię by Nvidia pokazała tabelkę na przykładzie przekroczenia cache... Jak już to pewnie zakładają brak potrzeby sięgania bezpośrednio do Vramu..., bo jest za dużo zmiennych przy przekroczeniu, aby to uwzględnić w prostej tabelce... Choćby różne opóźnienia dla gddr6, gddr6x, gddr7, przepustowość, stopień przekroczenia cache, rodzaj wyrzuconych danych do Vramu... Przekroczenie cache to spadek wydajności o kilka % i potencjalne rwanie, choć zależy ile i co wrzuciło do Vramu, bo może to być większy ubytek.
-
@sideband Dzięki za komentarz, ale dalej nie wiem czy się zrozumieliśmy... Przecież skądś kojarzę, że L2 jest wspólny dla wszystkich jednostek obliczeniowych... Chodzi mi o sposób obsługi, a nie budowę, gdy mówię o "wspólnym" L2. Wiem że cache ma niby nadrobić przepustowość pamięci od Ady, ale chodzi mi magazynowanie w nim elementów wymagających szybkiego dostępu... Ponoć od czasów Ampere można "rezerwować" cześć L2 np. dla elementów DLSS - wagi sieci neuronowej, wektory ruchu, buforowanie poprzednich klatek, gdzie w L2 są tylko aktualnie przetwarzane elementy lub tylko niektóre dane... Przejmowanie funkcji L1 to tylko jedna z czynności wykonywanej przez L2... Nadrabianie przepustowości to tylko jedna z funkcji... Tutaj kompletnie nie rozumiemy się, ponieważ dla mnie oczywiste jest, że chodzi o aktualnie przetwarzane elementy i małe, kluczowe rzeczy które można zmieścić w cache... Niektóre wymieniłem wyżej w tym komentarzu. Choćby cały bufor poprzedniej klatki nie będzie w cache, tylko potrzebne elementy. Edit. Na szybko z pomocą AI sporządziłem listę przykładowych rzeczy, które trafiają do cache, gwiazdka to funkcje wykonywane również przez L1: Edit.2 Również poprosiłem o tabelkę z oszacowanym zapotrzebowaniem na te elementy... Oczywiście im niższa rozdzielczość tym mniejsze zapotrzebowanie. Raczej nie bierze pod uwagę użycia FP8 w niektórych przypadkach:




